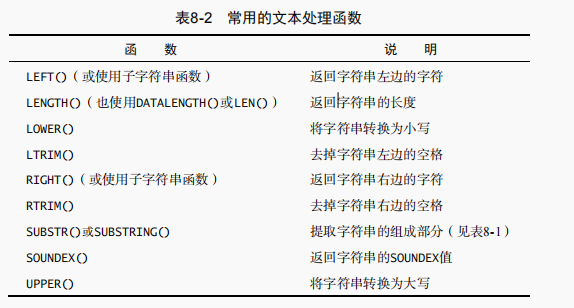
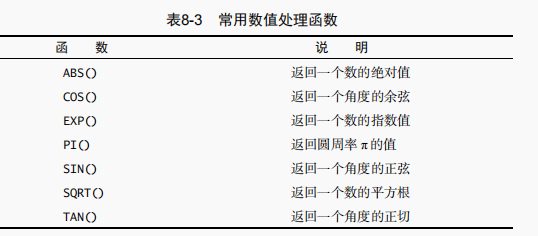
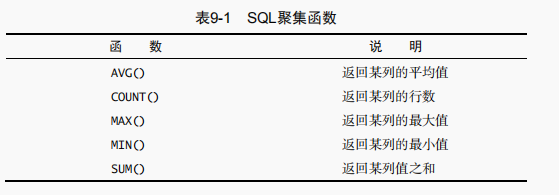
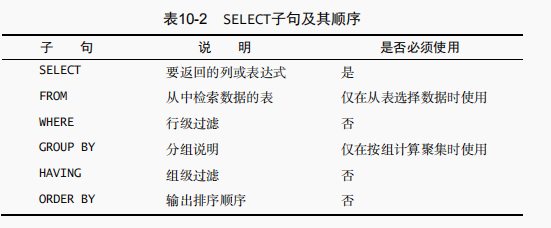
在指定一条 ORDER BY 子句时,应该保证它是 SELECT 语句中最后一条子句。如果它不是最后的子句,将会出错。
通常,ORDER BY 子句中使用的列将是为显示而选择的列。但是, 实际上并不一定要这样,用非检索的列排序数据是完全法的.
DESC只作用于选择的一列, 多选得每一项都加上DESC关键字.
挑战题
编写 SQL 语句,从 Customers 中检索所有的顾客名称(cust_names),并按从 Z 到 A 的顺序显示结果。
编写 SQL 语句,从 Orders 表中检索顾客 ID(cust_id)和订单号(order_num),并先按顾客 ID 对结果进行排序,再按订单日期倒序排列。
SELECTSUM(quantity) AS item_ordered FROM orderitems WHERE order_num =20005;
SELECTSUM(item_price*quantity) AS total_price FROM orderitems WHERE order_num =20005;
SUM()函数忽略列值为 NULL 的行。
聚集不同的值
1 2
SELECTAVG(DISTINCT prod_price) AS avg_price FROM products WHERE vend_id ='DLL01';
ALL 参数不需要指定,因为它是默认行为。如果不指定 DISTINCT,则假定为 ALL.
DISTINCT 只能指定列名用于 COUNT(), 不能用于 COUNT(*)。DISTINCT 必须使用列名,不能用于计算或表达式。
有的 DBMS 还支持其他参数,如支持对查询结果的子集进行计算的 TOP 和 TOP PERCENT。
组合聚集函数
1 2 3 4
SELECTCOUNT(*) AS num_items, MIN(prod_price) AS price_min, MAX(prod_price) AS price_max, AVG(prod_price) AS price_avg FROM products;
-- 挑战题 -- 1. SELECT order_num, COUNT(*) AS order_lines FROM orderitems GROUPBY order_num ORDERBY order_lines;
-- 2. SELECT vend_id, MIN(prod_price) AS cheapest_item FROM products GROUPBY vend_id ORDERBY cheapest_item DESC;
-- 3. SELECT order_num, SUM(quantity) AS total_quantity FROM orderitems GROUPBY order_num HAVINGSUM(quantity) >=100ORDERBY order_num;
-- 4. SELECT order_num, SUM(item_price*quantity) AS total_price FROM orderitems GROUPBY order_num HAVING total_price >=1000; -- GROUP BY clause must constains all nonaggregated column
-- 5. -- GROUP BY clause must constains all nonaggregated column
使用子查询
子查询过滤
1 2 3 4 5 6 7 8
SELECT cust_name, cust_contact FROM customers WHERE cust_id IN ( SELECT cust_id FROM orders WHERE order_num IN ( SELECT order_num FROM orderitems WHERE prod_id ='RGAN01' ) );
-- 挑战题 -- 1. SELECT cust_id FROM orders WHERE order_num IN (SELECT order_num FROM orderitems WHERE item_price >=10);
-- 2. SELECT cust_id, order_date FROM orders WHERE order_num IN -- 在orderitem中拿到'BR01'的 order_num (SELECT order_num FROM orderitems WHERE prod_id ='BR01') ORDERBY order_date;
-- 3. SELECT cust_id, cust_email FROM customers WHERE cust_id IN( SELECT cust_id FROM orders WHERE order_num IN( SELECT order_num FROM orderitems WHERE prod_id ='BR01'))
-- 4. SELECT cust_id, (SELECTSUM(quantity * item_price) FROM OrderItems WHERE order_num IN (SELECT order_num FROM Orders WHERE Orders.cust_id = Customers.cust_id)) AS total_ordered FROM Customers ORDERBY total_ordered DESC; -- 5. SELECT prod_name, (SELECTSUM(quantity) FROM orderitems WHERE orderitems.prod_id = products.prod_id ) AS quant_sold FROM products;
联结表
创建联结
1 2 3 4 5 6 7
SELECT vend_name, prod_name, prod_price FROM vendors, products WHERE vendors.vend_id = products.vend_id;
-- 直接这么写会得到笛卡尔积, WHERE 子句是查找过程中的过滤条件 SELECT* FROM vendors, products;
SELECT prod_name, vend_name, prod_price, quantity FROM orderitems, products, vendors WHERE products.vend_id = vendors.vend_id AND orderitems.prod_id = products.prod_id AND order_num =20007;
-- 子查询和联结比较 SELECT cust_name, cust_contact FROM customers WHERE cust_id IN ( SELECT cust_id FROM orders WHERE order_num IN ( SELECT order_num FROM orderitems WHERE prod_id ='RGAN01'));
SELECT cust_name, cust_contact FROM customers, orders, orderitems WHERE customers.cust_id = orders.cust_id AND orderitems.order_num = orders.order_num AND prod_id ='RGAN01';
-- 挑战题 -- 1. SELECT cust_name, order_num FROM customers, orders WHERE customers.cust_id = orders.cust_id ORDERBY cust_name, order_num;
SELECT cust_name, order_num FROM customers INNERJOIN orders ON customers.cust_id = orders.cust_id ORDERBY cust_name, order_num;
-- 2. SELECT cust_name, order_num, (SELECTSUM(quantity*item_price) FROM orderitems WHERE orderitems.order_num = orders.order_num) AS order_total FROM customers, orders WHERE customers.cust_id = orders.cust_id ORDERBY cust_name, order_num;
-- 时不我待 SELECT cust_name, orders.order_num, SUM(quantity*item_price) AS order_total FROM orders, orderitems, customers WHERE customers.cust_id = orders.cust_id AND orders.order_num = orderitems.order_num GROUPBY cust_name, orders.order_num ORDERBY cust_name, orders.order_num;
-- 这里的 GROUP BY 中 cust_name 其实可以不加 -- 可以这么理解:
-- a. 先进行笛卡尔积 SELECT* FROM orders, orderitems, customers WHERE customers.cust_id = orders.cust_id AND orders.order_num = orderitems.order_num -- b. 执行 WHERE 子句的过滤联结条件 WHERE customers.cust_id = orders.cust_id AND orders.order_num = orderitems.order_num -- c. 然后按cust_name 和 order_num 分组, 不分先后 由于order_num是结果中的主键, 按这种分组方式可映射多个 cust_name, 所以cust_name可有可无 GROUPBY cust_name, orders.order_num -- d. 返回选择的行, SUM()函数负责计算每个分组中的值 SELECT cust_name, orders.order_num, SUM(quantity*item_price) AS order_total
-- 3. SELECT order_date, cust_id FROM orders, orderitems WHERE orders.order_num = orderitems.order_num AND prod_id ='BR01' ORDERBY order_date;
SELECT order_date, cust_id FROM orders INNERJOIN orderitems ON orderitems.order_num = orders.order_num AND prod_id ='BR01' ORDERBY order_date; -- 有点意思
-- 4. SELECT customers.cust_id, cust_email FROM customers INNERJOIN orders ON orders.cust_id = customers.cust_id INNERJOIN orderitems ON orderitems.order_num = orders.order_num WHERE prod_id ='BR01';
-- 5. SELECT cust_name, SUM(item_price*quantity) AS total_price FROM orderitems INNERJOIN orders ON orders.order_num = orderitems.order_num INNERJOIN customers ON customers.cust_id = orders.cust_id GROUPBY cust_name HAVINGSUM(item_price*quantity) >=1000;
SELECT cust_name, SUM(item_price*quantity) AS total_price FROM orderitems, orders, customers WHERE orders.order_num = orderitems.order_num AND customers.cust_id = orders.cust_id GROUPBY cust_name HAVINGSUM(item_price*quantity) >=1000;
创建高级联结
使用表别名
1 2 3 4 5 6
SELECT cust_name, cust_contact -- 给表起 别名 AS, ORACLE的DB中可以不加AS FROM customers AS C, orders AS O, orderitems AS OI WHERE C.cust_id = O.cust_id AND OI.order_num = O.order_num AND prod_id ='RGAN01';
SQL 除了可以对列名和计算字段使用别名,还允许给表名起别名。这样做有两个主要理由:
缩短 SQL 语句;
允许在一条 SELECT 语句中多次使用相同的表。
表别名只在查询执行中使用。与列别名不一样,表别名不返回到客户端。
使用不同类型的联结
自联结(self-join)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
-- 使用自联结 SELECT c1.cust_id, c1.cust_name, c1.cust_contact FROM customers AS c1, customers AS c2 WHERE c1.cust_name = c2.cust_name AND c2.cust_contact ='Jim Jones';
-- OR 使用标准的内联结自联结 SELECT c1.cust_id, c1.cust_name, c1.cust_contact FROM customers AS c1 INNERJOIN customers AS c2 ON c1.cust_name = c2.cust_name AND c2.cust_contact ='Jim Jones';
-- 相同效果子查询, 在一张表中, 查找 cust_contact为某值的cust_name, 再由cust_name查找对应的信息 SELECT cust_id, cust_name, cust_contact FROM customers WHERE cust_name = (SELECT cust_name FROM customers WHERE cust_contact ='Jim Jones');
自然联结(natural join)
1 2 3 4 5 6 7 8 9 10 11 12
SELECT C.*, O.order_num, O.order_date, OI.prod_id, OI.quantity, OI.item_price FROM customers AS C, orders AS O, orderitems AS OI WHERE C.cust_id = O.cust_id AND OI.order_num = O.order_num AND prod_id ='RGAN01';
-- 等同于使用 JOIN SELECT customers.*, orders.order_num, orders.order_date, orderitems.prod_id,orderitems.quantity, orderitems.item_price FROM customers JOIN orders ON customers.cust_id = orders.cust_id JOIN orderitems ON orders.order_num = orderitems.order_num AND prod_id ='RGAN01';
SELECT customers.cust_id, orders.order_num FROM customers INNERJOIN orders ON customers.cust_id = orders.cust_id;
联结包含了那些在相关表中没有关联行的行。这种联结称为外联结.
左外联结和右外联结能相互转换.
使用带聚集函数的联结
1 2 3 4 5 6 7 8 9
SELECT customers.cust_id, COUNT(orders.order_num) AS num_ord FROM customers INNERJOIN orders ON customers.cust_id = orders.cust_id GROUPBY customers.cust_id;
SELECT customers.cust_id, COUNT(orders.order_num) AS num_ord FROM customers LEFTOUTERJOIN orders ON customers.cust_id = orders.cust_id GROUPBY customers.cust_id;
-- UNION 将两条SELECT的查询结果合并成一条 -- 等同于多个条件的 WHERE, 性能可能分情况有差别 SELECT cust_name, cust_contact, cust_email FROM customers WHERE cust_state IN ('IL', 'IN', 'MI') UNION SELECT cust_name, cust_contact, cust_email FROM customers WHERE cust_name ='Fun4ALL';
-- UNION ALL 不取消重复行 SELECT cust_name, cust_contact, cust_email FROM customers WHERE cust_state IN ('IL', 'IN', 'MI') UNIONALL SELECT cust_name, cust_contact, cust_email FROM customers WHERE cust_name ='Fun4All';
UNION 必须由两条或两条以上的 SELECT 语句组成,语句之间用关键字 UNION 分隔
UNION 从查询结果集中自动去除了重复的行, 行为与一条 SELECT 语句中使用多个 WHERE 子句一样.
如果确实需要每个条件的匹配行全部出现(包括重复行),就必须使用 UNION ALL,而不是 WHERE。
-- 组合查询只允许一条 ORDER BY, 放最后排序整个结果集 SELECT cust_name, cust_contact, cust_email FROM Customers WHERE cust_state IN ('IL','IN','MI') UNION SELECT cust_name, cust_contact, cust_email FROM Customers WHERE cust_name ='Fun4All' ORDERBY cust_name, cust_contact;
挑战题
编写 SQL 语句,将两个 SELECT 语句结合起来,以便从 OrderItems表中检索产品 ID(prod_id)和 quantity。其中,一个 SELECT 语句过滤数量为 100 的行,另一个 SELECT 语句过滤 ID 以 BNBG 开头的产品。按产品 ID 对结果进行排序。
下面的 SQL 语句有问题吗?(尝试在不运行的情况下指出。)
SELECT cust_name, cust_contact, cust_email
FROM Customers
WHERE cust_state = ‘MI’
ORDER BY cust_name;
UNION
SELECT cust_name, cust_contact, cust_email
FROM Customers
WHERE cust_state = 'IL’ORDER BY cust_name;
-- 挑战题 -- 1. SELECT prod_id, quantity FROM orderitems WHERE quantity =100 UNION SELECT prod_id, quantity FROM orderitems WHERE prod_id LIKE'BNBG%' ORDERBY prod_id;
-- 2. SELECT prod_id, quantity FROM orderitems WHERE quantity =100 ORDERBY prod_id;
SELECT prod_id, quantity FROM orderitems WHERE prod_id LIKE'BNBG%' ORDERBY prod_id;
-- 3. SELECT prod_name FROM products UNION SELECT cust_name FROM customers ORDERBY prod_name; -- that's nonsensial indeed, cust_name list in the list of prod_name
-- 利用视图简化复杂联结 CREATEVIEW prod_cust ASSELECT cust_name, cust_contact, prod_id FROM customers, orders, orderitems WHERE customers.cust_id = orders.cust_id AND orderitems.order_num = orders.order_num;
-- 删除视图 DROPVIEW prod_cust;
-- 对视图检索 SELECT cust_name, cust_contact FROM prod_cust WHERE prod_id ='RGAN01';
-- 使用视图重新格式化选择出来的数据 -- 在SELECT前面补上CREATE VIEW 语句就行了 CREATEVIEW vendor_locations AS SELECT CONCAT(vend_name, ' [ ', vend_country, ' ]') AS vend_title FROM vendors;
-- 使用视图过滤不想要的数据 CREATEVIEW cust_email_list AS SELECT cust_id, cust_name, cust_email FROM customers WHERE cust_email ISNOTNULL;
SELECT*FROM cust_email_list;
-- 使用视图与计算字段 CREATEVIEW order_items_expanded AS SELECT prod_id, quantity, item_price, quantity*item_price AS expanded_price FROM orderitems WHERE order_num =20008;
下面的 SQL 语句有问题吗?(尝试在不运行的情况下指出。)
CREATE VIEW OrderItemsExpanded AS
SELECT order_num,
prod_id,
quantity,
item_price,
quantity*item_price AS expanded_price
FROM OrderItems
ORDER BY order_num;
1 2 3 4 5 6 7 8 9
-- 挑战题 -- 1. CREATEVIEW cust_with_orders AS SELECT customers.*FROM customers JOIN orders ON customers.cust_id = orders.cust_id;
CREATEPROCEDURE IF NOTEXISTS HighPriceProd(IN price DECIMAL(8, 2)) BEGIN SELECT prod_id, prod_price FROM products WHERE prod_price >= price ORDERBY prod_price; END -- 删除 DROPPROCEDURE HighPriceProd; -- 调用 CALL HighPriceProd(5);
-- CREATEPROCEDURE SetPrice(IN pid CHAR(10), IN price DECIMAL(8,2)) BEGIN UPDATE products SET prod_price = price WHERE prod_id = pid; SELECT prod_id, prod_price FROM products; END