Java 笔记
泛型
泛型是Java5引进的新特征,是类和接口的一种扩展机制,主要实现参数化类型(parameterized type)机制。泛型被广泛应用在 Java 集合API 中,在Java集合框架中大多数的类和接口都是泛型类型。使用泛型,程序员可以编写更安全的程序.
泛型类型
泛型 (generics) 是带一个或多个类型参数 (type parameter) 的类或接口。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 interface Entry <K, V> { public K getKey () ; public V getValue () ; } class Pair <K, V> implements Entry <K, V> { private K key; private V value; public Pair (K key, V value) { this .key = key; this .value = value; } public void setKey (K key) {this .key = key;} public K getKey () {return key;} public void setValue (V value) {this .value = value;} public V getValue () {return value;} public <T> void getType (T t, K k, V v) { System.out.println(t.getClass().getName()); System.out.println(k.getClass().getName()); System.out.println(v.getClass().getName()); } } public class Main { public static void main (String[] args) { Pair<String, Integer> p_1 = new Pair <>("slacr" , 19 ); Pair<String, Integer> p_2 = new Pair <>("hacker" , 20 ); Pair<Pair, Pair> pp = new Pair <>(p_1, p_2); System.out.println(pp.getKey().getKey()); System.out.println(pp.getKey().getValue()); pp.<Integer>getType(2 , pp, p_1 ); } }
通配符’?’
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class Main { public static <T>void printList (List<T> list) { for (Object e : list) { System.out.println(e); } } public static void printList_1 (List<?> list) { for (Object e : list) { System.out.println(e); } } public static void main (String[] args) { List<String> list = new ArrayList <String>(); list.add("slacr" ); list.add("foo" ); list.add("bar" ); printList(list); printList_1(list); } }
有界类型参数
有界类型参数 (bounded type parameter)。 有界类型分为上界和下界,上界用 extends指定,下界用super指定。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class Main { public static <U extends Number & java.io.Serializable> double getAvg (List<U> list) { double total = 0D ; for (Number number : list) { total += number.doubleValue(); } return total/list.size(); } public static void main (String[] args) { List<Integer> integerList = new ArrayList <>(); integerList.add(1 ); integerList.add(2 ); integerList.add(3 ); System.out.println(getAvg(integerList)); List<Float> floatList = new ArrayList <>(); floatList.add(3F ); floatList.add(4F ); System.out.println(getAvg(floatList)); } }
类型擦除
当实例化泛型类型时,编译器使用一种叫类型擦除 (type erasure)的技术转换这些类型。在编译时,编译器将清除类和方法中所有与类型参数有关的信息。类型擦除可让使用泛型的Java应用程序与之前不使用泛型类型的 Java类库和应用程序兼容
例如,Node<Integer>被转换成 Node, 它称为源类型 (raw type)。源类型是不带任何类型参数的泛型类或接口名。这说明在运行时找不到泛型类使用的是什么类型。
也就是说泛型类在编译时泛型参数的类型是不可确定的, 只有在实例化对象时才能确定, 因此定义泛型类或方法的时候只能声明存在该参数类型的变量, 而不能直接使用, 像 new T() 或者赋值.
集合框架
Java 提供了一个集合框架 (Collections Framework), 该框架定义了一组接口和类, 使得处理对象组更容易。
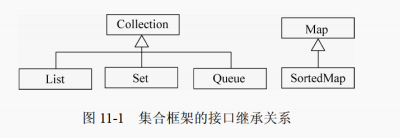
集合是指集中存放一组对象的一个对象。集合相当于一个容器,提供了保存、获取和操作其他元素的方法。集合能够帮助Java程序员轻松地管理对象。 Java 集合框架由两种类型构成,一个是Collection; 另一个是Map。Collection 对象用于存放一组对象, Map 对象用于存放一组“关键字/值”的对象。 Collection和 Map 是最基本的接口,它们又有子接口.
Collection接口是所有集合类型的根接口,继承了 Iterable接口. Collection接口定义了集合操作的常用方法,这些方法可以简单分为基本操作、批量操作、数组操作和流操作。
基本操作
boolean add(E e)
boolean remove(Object o)删除首次出现元素 o
boolean contains(Object o)返回集合中是否包含指定的元素o。
boolean isEmpty()
int size()
Iterator iterator()返回包含所有元素的迭代器对象。
default void forEach(Consumer<? super T>action)从父接口继承的方法,在集合的每个元素上执行指定的操作。
批量操作
boolean addAll(Collection<? extends E> c)将集合 c 中的所有元素添加到当前集合中。
boolean removeAll(Collection<?>c)从当前集合中删除c 中的所有元素。
default boolean removeif(Predicate<? super E> filter)从当前集合中删除满足谓词的所有元素。
boolean containsAll(Collection<?>c)返回当前集合是否包含c 中的所有元素。
boolean retainAll(Collection<?>c)在当前集合中只保留指定集合 c 中的元素,其他元素删除。
void clear()
数组操作
Object[] toArray()返回包含集合中所有元素的对象数组。
<T>T[] toArray(T[] a)返回包含集合中所有元素的数组,返回数组的元素类型是指定的数组类型
Object[] a = c.toArray(); 将Collection对象转换为Object数组.
流(Stream)操作
public default Stream<E> stream()以当前集合作为源返回一个顺序 Stream对象。
public default Stream<E> paralellStream()以当前集合作为源返回一个并行 Stream对象。
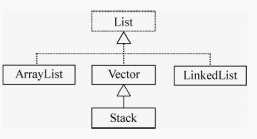
List 接口及实现类
List接口是 Collection的子接口,实现一种线性表的数据结构.
List 接口除继承 Collection的方法外,还定义了一些自己的方法。
E get(int index)
E set(int index,E element)
void add(int index, E element)
E remove(int index)
abstract boolean addAll(int index, Collection<? extends E> c)在指定下标处插入集合c 中的全部元素。
int indexOf(Object o)查找指定对象第一次出现的位置。
int lastIndexOf(Object o)
List<E>subList(int from,int to)
default void replaceAll(UnaryOperator<E> operator)将操作符应用于元素,并使用其结果替代每个元素。
1 2 3 4 5 6 7 8 9 10 public class Main { public static void main (String[] args) { List<Character> characterList = new ArrayList <>(10 ); for (int i = 0 ; i < 10 ; i++) { characterList.add((char )('A' +i)); System.out.println(characterList.get(i)); } } }
ArrayList类
ArrayList是最常用的线性表实现类,通过数组实现的集合对象。 ArrayList类实际上实现了一个变长的对象数组,其元素可以动态地增加和删除。它的定位访问时间是常量时间。
ArrayList() 创建一个空的数组线性表对象,默认初始容量是10。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class Main { public static void main (String[] args) { ArrayList<String> stringArrayList = new ArrayList <>(); stringArrayList.add("how " ); stringArrayList.add("are " ); stringArrayList.add("you " ); for (String s : stringArrayList) { System.out.print(s); } System.out.println(); stringArrayList.forEach((s) -> System.out.print(s)); System.out.println(); stringArrayList.forEach(System.out::print); } }
使用迭代器
迭代器是一个可以遍历集合中每个元素的对象。调用集合对象的 iterator() 方法可以得到 Iterator对象
boolean hasNext()返回迭代器中是否还有对象。
E next()返回迭代器中下一个对象。
void remove()删除迭代器中的当前对象
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class Main { public static void main (String[] args) { ArrayList<String> stringArrayList = new ArrayList <>(); stringArrayList.add("how " ); stringArrayList.add("are " ); stringArrayList.add("you " ); Iterator<String> stringIterator = stringArrayList.iterator(); stringIterator.next(); stringIterator.remove(); while (stringIterator.hasNext()) { System.out.printf(stringIterator.next()); } } }
双向迭代器
List还提供了listIterator() 方法返回ListIterator对象。它可以从前后两个方向遍历线性表中元素,在迭代中修改元素以及获得元素的当前位置。ListIterator是Iterator的子接口,不但继承了Iterator接口中的方法,还定义了自己的方法。
E next()返回下一个元素。
boolean hasPrevious()返回是否还有前一个元素。
E previous()返回前一个元素。
int nextIndex()返回下一个元素的索引。
int previousIndex()返回前一个元素的索引。
void remove()删除当前元素。
void set(E o)修改当前元素。
void add(E o)在当前位置插入一个元素
使用迭代器可以修改线性表中的元素,但不能同时使用两个迭代器修改一个线性表中的元素,否则将抛出异常。
1 2 3 4 5 6 7 8 9 10 11 12 public class Main { public static void main (String[] args) { ArrayList<String> stringArrayList = new ArrayList <>(); stringArrayList.add("how " ); stringArrayList.add("are " ); stringArrayList.add("you " ); ListIterator<String> stringListIterator = stringArrayList.listIterator(); while (stringListIterator.hasNext()) stringListIterator.next(); while (stringListIterator.hasPrevious()) System.out.println(stringListIterator.previous()); } }
数组转List对象
java.util.Arrays 类提供了一个 asList()方法,实现将数组转换成 List对象的功能.
public static <T> List<T> asList(T ...a)
该方法提供了一个从多个元素创建 List 对象的途径,它的功能与 Collection 接口的 toArray()方法相反.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class Main { public static void main (String[] args) { ArrayList<String> stringArrayList = new ArrayList <>(); stringArrayList.add("how " ); stringArrayList.add("are " ); stringArrayList.add("you " ); String[] strings = stringArrayList.toArray(new String [0 ]); for (String string : strings) { System.out.print(string + " " ); } System.out.println(); List<String> stringList = Arrays.asList(strings); stringList.forEach(System.out::print); List<String> stringList1 = Arrays.asList("seize" , "the" , "moment" ); stringList1.forEach(s->{System.out.print(s + " " );}); } }
Vector 和 Stack
Vector类和Stack类是Java早期版本提供的两个集合类,分别实现向量和对象栈。Vector类和 Stack类的方法都是同步的,适合在多线程的环境中使用.
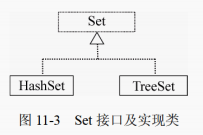
Set接口及其实现类
Set 接口是 Collection的子接口,Set 接口对象类似于数学上的集合概念,其中不允许有重复的元素。 Set 接口没有定义新的方法,只包含从Collection接口继承的方法。HashSet 类、 TreeSet 类和 LinkedHashSet类 。
HashSet 类
HashSet类用散列方法存储元素,具有最好的存取性能,但元素没有顺序。
HashSet() 创建一个空的散列集合,该集合的默认初始容量是16, 默认装填因子(loadfactor) 是0.75。装填因子决定何时对散列表进行再散列。例如,如果装填因子为0.75(默认值), 而表中超过75%的位置已经填入元素,这个表就会用双倍的桶数自动地进行再散列。对于大多数应用程序来说,装填因子为75%是比较合理的。
HashSet(Collection c)用指定的集合c 的元素创建一个散列集合。
HashSet(int initialCapacity)创建一个散列集合,并指定集合的初始容量。
HashSet(int initialCapacity, float loadFactor)创建一个散列集合,并指定的集合初始容量和装填因子
1 2 3 4 5 6 7 8 9 10 11 12 public class Main { public static void main (String[] args) { Set<String> words =new HashSet <>(); words.add("one" ); words.add("two" ); words.add("three" ); words.add("one" ); for (String word : words) { System.out.println(word); } } }
用 Set 对象实现集合运算
sl.addAll(s2)实现集合sl 与 s2 的并运算。
sl.retainAll(s2)实现集合 s1与 s2 的交运算。
sl.removeAll(s2)实现集合 s1 与 s2 的差运算。
sl.containAll(s2)如果 s2是 s1 的子集,该方法返回 true。
TreeSet 类
TreeSet实现一种树集合,使用红-黑树为元素排序,添加到 TreeSet 中的元素必须是可比较的,即元素的类必须实现 Comparable<T> 接口。它的操作要比 HashSet 慢。
TreeSet(Collection c)用指定集合c 中的元素创建一个新的树集合,集合中的元素按自然顺序排序。
TreeSet(Comparator c)创建一个空的树集合,元素的排序规则按给定的比较器c 的规则排序。
TreeSet(SortedSet s)用 SortedSet 对象 s 中的元素创建一个树集合,排序规则与 s 的排序规则相同。
E first()返回有序集合中的第一个元素。
E last()返回有序集合中最后一个元素。
SortedSet<E> subSet(E fromElement, E toElement)返回有序集合中的一个子有序集合,它的元素从 fromElement 开始到 toElement结束(不包括最后元素)。
SortedSet<E> headSet(E toElement)返回有序集合中小于指定元素 toElement 的一个子有序集合。
SortedSet<E> tailSet(E fromElement)返回有序集合中大于等于 fromElement 元素的子有序集合。
Comparator<? super E> comparator()返回与该有序集合相关的比较器,如果集合使用自然顺序则返回 null
1 2 3 4 5 6 7 8 9 10 11 12 public class Main { public static void main (String[] args) { String[] strings = {"Swift" , "TypeScript" , "Scala" , "Lisp" , "VBScript" , "Basic" }; TreeSet<String> stringSet = new TreeSet <>(); for (int i = 0 ; i < strings.length; i++) { stringSet.add(strings[i]); } System.out.println(stringSet); SortedSet<String> sortedSet = stringSet.subSet("Lisp" , "Swift" ); System.out.println(sortedSet); } }
对象顺序
创建 TreeSet 类对象时如果没有指定比较器对象,集合中的元素按自然顺序排列。所谓自然顺序(natural order)是指集合对象实现了 Comparable 接口的 compareTo()方法,对象则根据该方法排序。如果试图对没有实现 Comparable 接口的集合元素排序,将抛出ClassCastException 异常。另一种排序方法是创建 TreeSet 对象时指定一个比较器对象,这样,元素将按比较器的规则排序。如果需要指定新的比较规则,可以定义一个类实现Comparator 接口,然后为集合提供一个新的比较器.
1 2 3 4 5 6 7 8 9 10 11 12 13 public class Main { public static void main (String[] args) { String[] strings = {"Swift" , "TypeScript" , "Scala" , "Lisp" , "VBScript" , "Basic" }; TreeSet<String> stringSet = new TreeSet <>((String s1, String s2) -> s2.compareTo(s1)); for (int i = 0 ; i < strings.length; i++) { stringSet.add(strings[i]); } System.out.println(stringSet); } }
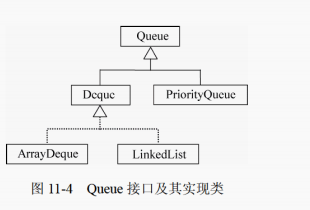
Queue 接口及其实现类
Queue接口是Collection的子接口,是以先进先出 (first in first out,FIFO)的方式排列其元素,一般称为队列。
Deque 接口对象实现双端队列,ArrayDeque 和 LinkedList 是它的两个实现类。
Queue 接口和 Deque 接口
Queue 接口除了提供 Collection的操作外, 还提供了插入、删除和检查操作。
boolean add(E e)
boolean offer(E e)将指定的元素 e 插入到队列中。 失败add抛出异常, offer返回false
E remove()返回队列头元素,同时将其删除。
E poll()返回队列头元素,同时将其删除。 失败remove抛出异常, poll返回null
E element()返回队列头元素,但不将其删除。
E peek() 返回队列头元素,但不将其删除。 失败element抛出异常, peek返回null
Queue 接口的每种操作都有两种形式:一个是在操作失败时抛出异常;另一个是在操作失败时返回一个特定的值(根据操作的不同,可能返回 null或 false)
Deque 接口实现双端队列,支持从两端插入和删除元素,同时实现了 Stack 和 Queue 的功能。
第一个方法在操作失败时抛出异常;第二个方法操作失败返回一个特殊值。除表中定义的基本方法外, Deque 接口还定义了 removeFirstOccurence() 和 removeLastOccurence()方法,分别用于删除第一次出现的元素,删除最后出现的元素.
ArrayDeque 类和 LinkedList 类
Deque 的常用实现类包括 ArrayDeque类和LinkedList类,前者是可变数组的实现;后者是线性表的实现。LinkedList类比 ArayDeque类更灵活,实现了线性表的所有操作,其中可以存储null元素,但ArrayDeque 对象不能存储null.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public class Main { public static void main (String[] args) { ArrayDeque<String> arrayDeque = new ArrayDeque <>(); arrayDeque.add("till " ); arrayDeque.offerFirst("it " ); arrayDeque.addFirst("fake " ); arrayDeque.offerLast("you " ); arrayDeque.add("make " ); arrayDeque.addLast("it. " ); arrayDeque.forEach(System.out::print); arrayDeque.forEach(new Consumer <String>() { @Override public void accept (String s) { System.out.print(s); } }); arrayDeque.forEach(x -> System.out.print(x)); Iterator<String> stringIterator = arrayDeque.iterator(); while (stringIterator.hasNext()) System.out.print(stringIterator.next()); for (String s : arrayDeque) { System.out.print(s);} } }
LinkedList允许null元素, 如果需要经常在线性表的头部添加元素或在内部删除元素,就应该使用LinkedList。这些操作在LinkedList中是常量时间,在ArrayList中是线性时间。而对定位访问LinkedList是线性时间,ArrayList是常量时间。LinkedList 同时实现了List 接口和Queue 接口.
LinkedList()LinkedList(Collection c)addFirst()、getFirst()、removeFirst()、addLast()、getLast() removeLast()…
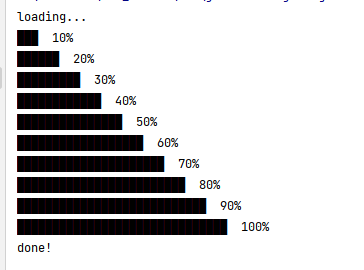
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class Main { public static void main (String[] args) throws InterruptedException { Queue<String> stringQueue = new LinkedList <>(); final int count = 10 ; stringQueue.add("loading..." ); String bar = "██████████████████████████████" ; for (int i = 3 ; i < bar.length() + 1 ; i+= 3 ) { stringQueue.add(bar.substring(0 ,i) + " " + i/3 *10 + "%" ); } stringQueue.add("done!" ); while (!stringQueue.isEmpty()) { System.out.println(stringQueue.remove()); Thread.sleep(1000 ); } } }
集合转换
集合实现类的构造方法可以接收一个Collection对象, 转换成该类型的集合. 所以许多集合类型之间可以相互转换.
public ArrayList(Collection c)public HashSet(Collection c)public LinkedList(Collection c)
1 2 3 4 5 6 7 8 9 10 11 public class Main { public static void main (String[] args) { HashSet<Integer> integerHashSet = new HashSet <>(); integerHashSet.add(1 ); integerHashSet.add(2 ); LinkedList<Integer> integerLinkedList = new LinkedList <>(integerHashSet); integerLinkedList.add(3 ); integerLinkedList.add(4 ); System.out.println(integerLinkedList); } }
Map 接口及其实现类
Map 是用来存储“键/值”对的对象。在 Map 中存储的关键字和值都必须是对象,并要求关键字唯一的,而值可以重复.
基本操作
public V put(K key, V value)向映射对象中添加一个“键/值”对。
public V get(Object key)返回指定键的值。
public V remove(Object key)
public boolean containsKey(Object key)
public boolean containsValue(Object value)
default V replace(K key,V value)若指定的“键/值”对存在于映射中,用指定的“键/值"对替换之。
default void forEach(BiConsumer<? super K,? super V)对映射中的每项执行一次动作,直到所有项处理完或发生异常。
public int size()
public boolean isEmpty()
批量操作
public void putAll(Map<? extends K,? extends V> map)将参数 map 中的所有“键/值"对添加到映射中。
public void clear()
public Set<K>keySet()返回由键组成的 Set对象。
public Collection<V>values()返回由值组成的 Collection对象。
public Set<Map.Entry<K,V>>entrySet()返回包含 Map.Entry<K,V>的一个 Set对象
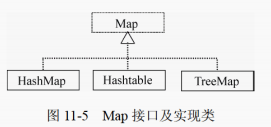
Map 接口实现类
常用实现类有HashMap、TreeMap和 Hashtable类
HashMap 类
HashMap类以散列方法存放“键/值”对
HashMap() 创建一个空的映射对象,使用默认的装填因子(0.75)。HashMap(int initialCapacity) 用指定初始容量和默认装填因子创建一个映射对象。HashMap(Map m)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class Main { public static void main (String[] args) { ArrayList<String> nameList = new ArrayList <>(Arrays.asList("slacr" , "John" , "Amy" , "Tim" )); ArrayList<Integer> scoreList = new ArrayList <>(Arrays.asList(60 , 53 , 88 , 99 )); Map<String, Integer> map = new HashMap <>(); for (int i = 0 ; i < nameList.size(); i++) { map.put(nameList.get(i), scoreList.get(i)); } map.forEach((k, v) -> { System.out.printf("%-10s%d\n" , k, v);}); } }
TreeMap 类
TreeMap 类实现了SortedMap 接口,保证Map 中的“键/值”对按关键字升序排序。
TreeMap()TreeMap(Comparator c)TreeMap(Map m)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class Main { public static void main (String[] args) { ArrayList<String> nameList = new ArrayList <>(Arrays.asList("slacr" , "John" , "Amy" , "Tim" )); ArrayList<Integer> scoreList = new ArrayList <>(Arrays.asList(60 , 53 , 88 , 99 )); TreeMap<String, Integer> map = new TreeMap <>(new Comparator <String>() { @Override public int compare (String o1, String o2) { return scoreList.get(nameList.indexOf(o2)) - scoreList.get(nameList.indexOf(o1)); } }); for (int i = 0 ; i < nameList.size(); i++) { map.put(nameList.get(i), scoreList.get(i)); } map.forEach(new BiConsumer <String, Integer>() { static int i = 1 ; public void accept (String k, Integer v) { System.out.printf("No.%-5d%-10s%d\n" ,i, k, v); i++; } }); } }
Hashtable 类和 Enumeration 接口
Hashtable类是 Java 早期版本提供的一个存放“键/值”对的实现类,实现了一种散列表,也属于集合框架。Hashtable类的方法都是同步的,因此它是线程安全的。hashCode()方法和equals()方法,以使对象的比较成为可能。Enumeration 接口类型的对象,通过该接口中hasMoreElements()方法和nextElement()方法可以对枚举对象元素迭代
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 public class Main { public static void main (String[] args) { Hashtable<Integer, String> hashtable = new Hashtable <>(); hashtable.put(1 , "王二" ); hashtable.put(2 , "陈清扬" ); hashtable.put(3 , "罗小四" ); hashtable.put(4 , "军代表" ); hashtable.put(5 , "敦敦伟大友谊" ); String s = hashtable.get(5 ); System.out.println(s); Enumeration<String> words = hashtable.elements(); while (words.hasMoreElements()) System.out.println(words.nextElement()); hashtable.forEach((k, v) -> System.out.println(k + " " + v)); for (Integer k : hashtable.keySet()) System.out.print(k + " " ); System.out.println(); hashtable.keySet().forEach(i-> System.out.print(i+" " )); System.out.println(); for (Iterator<Integer> it = hashtable.keySet().iterator(); it.hasNext(); ) System.out.print(it.next()+" " ); System.out.println(); hashtable.values().forEach(System.out::println); hashtable.entrySet().forEach((Map.Entry<Integer, String> entry) -> { System.out.println(entry.getKey() + " " + entry.getValue()); }); } }
Collections 类
Collections类是java.util包中定义的工具类,这个类提供了若干static方法实现集合对象的操作。这些操作大多对List操作,主要包括排序、重排、查找、求极值以及常规操作等。
排序
public static<T>void sort(List<T>list)
public static<T> void sort(List<T>list, Comparator<? super T>c)
查找
public static<T> int binarySearch(List<T> list, T key)List需要sorted 如果 List包含要查找的元素,方法返回元素的下标,否则返回值为(-插入点-1)
public static <T>int binarySearch(List<T> list, T key, Comparator c)
打乱元素次序
public static void shuffle(List<?> list)使用默认的随机数打乱 List中元素的次序。
public static void shuffle(List<?> list, Random rnd)使用指定的Random 对象,打乱List 中元素的次序
求极值
public static <T>T max(Collection<? extends T>coll)
public static <T>T max(Collection<? extends T> coll, Comparator<? super T> comp)
public static <T>T min(Collection<? extends T>coll)
public static <T>T min(Collection<? extends T>coll, Comparator<? super T>comp)
其他常用
public static void reverse(List<?>list)
public static void fill(List<? super T>list,T obj)用指定的值覆盖List中原来的每个值,该方法主要用于对 List进行重新初始化。
public static void copy(List<? super T> dest,List<? extends T> src)
public static void swap(List<?>list, int i, int j)
public static void rotate(List<?> list, int distance)旋转列表,将 i 位置的元素移动到(i+distance)%list.size() 的位置。
public static <T> boolean addAll(Collection<? super T>c, T ...elements)该方法用于将指定的元素添加到集合 c 中,可以指定单个元素或数组。
public static int frequency(Collection<?>c, Object o)返回指定的元素o 在集合c 中出现的次数。
public static boolean disjoint(Collection<?>cl, Collection<?>c2)判断两个集合是否不相交。如果两个集合不包含相同的元素,该方法返回 true。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public class Main { public static void main (String[] args) { ArrayList<Integer> integerArrayList = new ArrayList <>(Arrays.asList(2 ,3 ,1 ,5 ,4 ,7 ,6 )); Collections.sort(integerArrayList, Comparator.reverseOrder()); System.out.println(integerArrayList); Collections.shuffle(integerArrayList); System.out.println(integerArrayList); Collections.reverse(integerArrayList); System.out.println(integerArrayList); Map<String, Integer> map = new HashMap <>(); for (int i = 0 ; i < 4 ; i++) { map.put(new ArrayList <>(Arrays.asList("slacr" , "John" , "Amy" , "Tim" )).get(i), new ArrayList <>(Arrays.asList(60 , 53 , 88 , 99 )).get(i)); } System.out.println(Collections.max(map.entrySet(), (entry1, entry2) -> { return entry1.getValue() - entry2.getValue(); })); } }
Stream API
流 (stream) 就像一个管道,将数据从源传输到目的地。流可分为顺序流和并行流。用来移动数据,因此不能像集合一样向流中添加元素
Stream 的有些方法执行中间操作,有些方法执行终止操作。中间操作是将一个流转换成另一个流,sorted、filter和 map 方法执行中间操作。终止操作产生一个最终结果, count、forEach 方法执行终止操作。流操作是延迟的,在源上的计算只有当终止操作开始时才执行.
创建与获得流
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class Main { public static void main (String[] args) { Stream<Integer> stream = Stream.of(1 , 2 , 3 ); String[] strings = {"Victor" , "Deque" , "Set" , "Map" }; Stream<String> stringStream = Arrays.stream(strings); Stream<Double> randoms = Stream.generate(Math::random); Stream<BigInteger> integerStream = Stream.iterate(BigInteger.ZERO, n->n.add(BigInteger.ONE)); } }
连接与限制流
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class Main { public static void main (String[] args) { Stream<Integer> s1 = Stream.of(1 , 2 ); Stream<Integer> s2 = Stream.of(4 , 3 ); Stream<Integer> s3 = Stream.of(6 , 5 ); Stream.concat(Stream.concat(s1, s2), s3).sorted(Comparator.reverseOrder()).forEach(System.out::print); System.out.println(); Stream<Double> randoms = Stream.generate(() -> Double.valueOf(String.format("%.2f" , Math.random()))).limit(10 ); randoms.forEach(System.out::println); } }
过滤流
1 2 3 4 5 6 7 8 9 10 11 public class Main { public static void main (String[] args) throws IOException { Stream<Integer> stream = Stream.of(1 , 2 , 3 , 4 , 5 ); stream = stream.filter(i -> i>3 ); stream.forEach(System.out::println); Path parent = Paths.get(".." ); Stream<Path> list = Files.walk(parent); list.filter((Path p) -> p.toString().endsWith(".java" )).forEach(System.out::println); } }
流转换
1 2 3 4 5 6 7 8 public class Main { public static void main (String[] args) { Stream<Character> characterStream = Stream.of('A' , 'B' , 'C' ); Stream<Integer> integerStream = characterStream.map((character -> {return Integer.valueOf(character);})); integerStream.forEach(System.out::println); } }
流规约
经常需要从流中获得一个结果,如返回流中元素的数量。此时,可以使用流的 count()方法实现。这样的方法称为规约方法 (reduction),规约是终止操作。Stream接口提供了几个简单的规约方法,除count()方法外,还有max()和min()方法,它们分别返回流中的最大值和最小值。需要注意的是,这两个方法返回一个Optional类型的值,它可能会封装返回值,也可能表示没有返回(当流为空时).
1 2 3 4 5 6 7 8 9 10 11 12 public class Main { public static void main (String[] args) { Stream<Character> characterStream = Stream.of('A' , 'B' , 'C' ); Stream<Integer> integerStream = characterStream.map((character -> {return Integer.valueOf(character);})); System.out.println(integerStream.max(Comparator.reverseOrder()).get()); } }
收集结果
当处理完流后,可能需要查看结果或将结果收集到其他容器中。可以使用 iterator()方法,该方法可以生成一个能够用来访问元素的传统迭代器。不可能在运行时创建一个泛型数组,所以表达式 stream.toArray()返回一个 Object[]类型数组。如果想获得相应类型数组,可以将类型传递给数组的构造方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public class Main { public static void main (String[] args) { Stream<String> stringStream = Stream.of("gone" , "with" , "the" , "wind" ); String[] res = stringStream.toArray(String[]::new ); ArrayList<String> arrayList = new ArrayList <>(List.of(res)); System.out.println(arrayList); Stream<String> stringStream1 = Stream.of("gone" , "with" , "the" , "wind" ); LinkedList linkedList = new LinkedList <>(stringStream1.toList()); System.out.println(linkedList); Stream<String> stringStream2 = Stream.of("gone" , "with" , "the" , "wind" ); List<String> list = stringStream2.collect(Collectors.toList()); System.out.println(list); Stream<String> stringStream3 = Stream.of("gone" , "with" , "the" , "wind" ); Set<String> set = stringStream3.collect(Collectors.toSet()); System.out.println(set); Stream<String> stringStream4 = Stream.of("gone" , "with" , "the" , "wind" ); TreeSet treeSet = stringStream4.collect(Collectors.toCollection(TreeSet::new )); System.out.println(treeSet); } }
基本类型流
对于基本类型,可以使用其包装类创建流,如 Stream。为了直接将基本类型值存储到流中而不需要进行包装,Stream类库提供了IntStream、LongStream DoubleStream类型,对 short、char、byte、boolean类型使用 IntStream类型,对 float使用DoubleStream类型
当拥有一个对象流时,可以使用 mapToInt()、mapToLong()或mapToDouble() 方法将其转换成基本类型流.Stream<String> words = Stream.of("this","is","a","java","string");IntStream lengths = words.mapToInt(String::length);
要将一个基本类型流转换成一个对象流,可以使用 boxed()方法。Stream<Integer> integers = IntStream.range(0,100).boxed();
Random 类中提供了 ints()、longs()、doubles() 方法,它们返回包含随机数的基本类型流.
并行流
可以并行执行多个线程, 流使得并行计算变得容易。
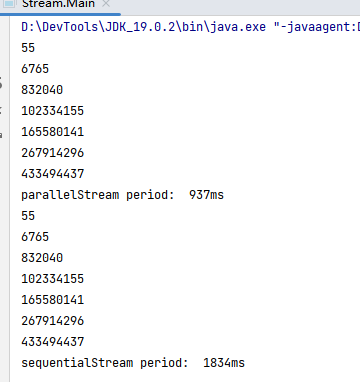
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public class Main { public static long fibonacci (long n) { if ( n == 1 || n == 2 ) { return 1 ; } return fibonacci(n-1 ) + fibonacci(n-2 ); } public static void main (String[] args) { List<Integer> nums = Arrays.asList(10 , 20 , 30 ,40 , 41 , 42 , 43 ); Instant start = Instant.now(); nums.parallelStream().map(i->fibonacci(i)).forEach(System.out::println); Instant end = Instant.now(); System.out.println("parallelStream period: " + Duration.between(start, end).toMillis() + "ms" ); start = Instant.now(); nums.stream().map(i->fibonacci(i)).forEach(System.out::println); end = Instant.now(); System.out.println("sequentialStream period: " + Duration.between(start, end).toMillis() + "ms" ); } }
从结果可以看到,使用并行流计算时间要比使用顺序流短。使用并行流时,输出也可能不是按顺序输出的。
知识点
接口或者更普遍的抽象类, 不能直接实例化对象是应为其中的抽象方法需要实现, 有两种方法可以创建抽象类的对象, 第一种最常见的使用非抽象的子类上转型, 第二种用new初始化的时候给出匿名实现类(相当于给出抽象方法的实现).
参考
《Java程序设计(第3版)》 IBSN 9787302485520
Java API 文档