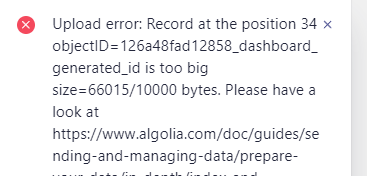
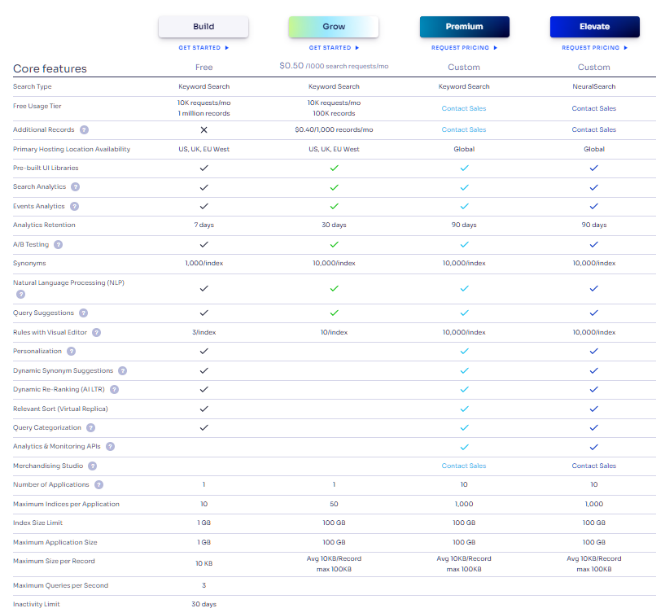
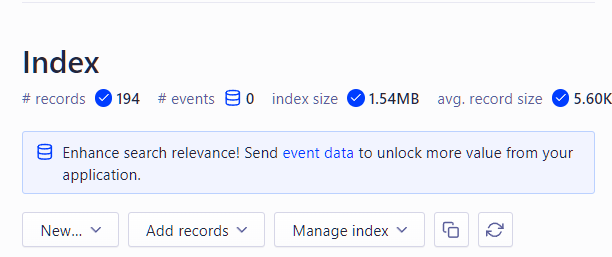
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
|
import json
from pprint import pprint
MAXSIZE = 7500
new_json = []
def cut_content(encoded_content):
'''分隔utf-8编码成为指定大小的元素的列表'''
unit_length = MAXSIZE
decoded_list = []
start_index = 0
end_index = start_index + unit_length
while start_index < len(encoded_content):
if end_index > len(encoded_content):
end_index = len(encoded_content)
try:
decoded_string = encoded_content[start_index:end_index].decode(
'utf-8')
decoded_list.append(decoded_string)
except UnicodeDecodeError:
end_index -= 1
else:
start_index = end_index
end_index = start_index + unit_length
return decoded_list
def add_new_entries(content_list, old_entry):
'''组成新的条目并添加到new_json'''
new_entry = old_entry.copy()
del new_entry['content']
for idx, s in enumerate(content_list):
entry = new_entry.copy()
entry["idx"] = idx
entry["content"] = s
new_json.append(entry)
def gene_file():
'''生成新json文件'''
with open('./data.json', 'w', encoding='utf-8') as file:
json.dump(new_json, file, ensure_ascii=False, indent=4)
def main():
with open('./c2VhcmNo.json', 'r', encoding='utf-8') as json_file:
json_data = json.load(json_file)
for i in range(len(json_data)):
content = json_data[i]["content"]
encoded_content = content.encode('utf-8')
psize = len(encoded_content)
if psize > MAXSIZE:
content_list = cut_content(encoded_content)
add_new_entries(content_list, json_data[i])
else:
new_json.append(json_data[i])
gene_file()
if __name__ == "__main__":
main()
|