TensorFlow assignment with AIGC
环境
Windows 11 23H2 希冀平台 VisualStudioCode 1.85.1 Python 3.9 TensorFlow2.9.0
Tensorflow-gpu 2.7.0 cudatoolkit11.8.0
深度学习与实践基础实验
图像增强
实现均值滤波
首先定义了一个 3x3 的均值滤波模板 kernel,它的每个元素都是 1/9,用于计算每个像素的均值。然后,使用 cv2.filter2D 函数将模板应用到图像上,得到均值滤波后的结果 output。
使用 cv2.cvtColor 函数将图像从 BGR 格式转换为 RGB 格式,因为 Matplotlib 默认使用 RGB 格式来显示图像。
最后,使用 plt.imshow 函数分别显示原始图像 img2 和均值滤波后的图像 output2。
1 | import cv2 |
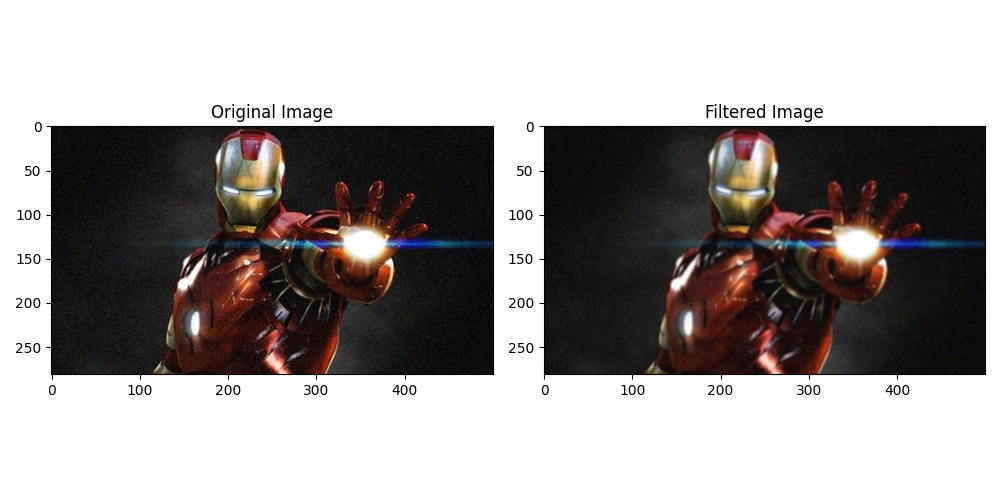
使用了均值滤波来处理了图像。均值滤波是一种常用的图像平滑处理方法,它可以减少图像中的噪声,并使图像变得更加模糊。
根据以上代码中的均值滤波模板(3x3 的全1矩阵除以9),我们可以看到滤波后的图像输出变得更加模糊。这是因为均值滤波将每个像素周围的邻域取平均值,从而减少了像素值之间的差异。
实现图像锐化
首先读取图像,并将其转换为灰度图像。定义了自己的Sobel算子,分别为x方向和y方向。接下来使用cv2.filter2D函数对灰度图像进行卷积计算,分别得到x方向和y方向的卷积结果。然后对卷积结果取绝对值并转换为8位图像。最后将x方向和y方向的卷积结果加权相加,得到最终的锐化图像。
1 | import cv2 |
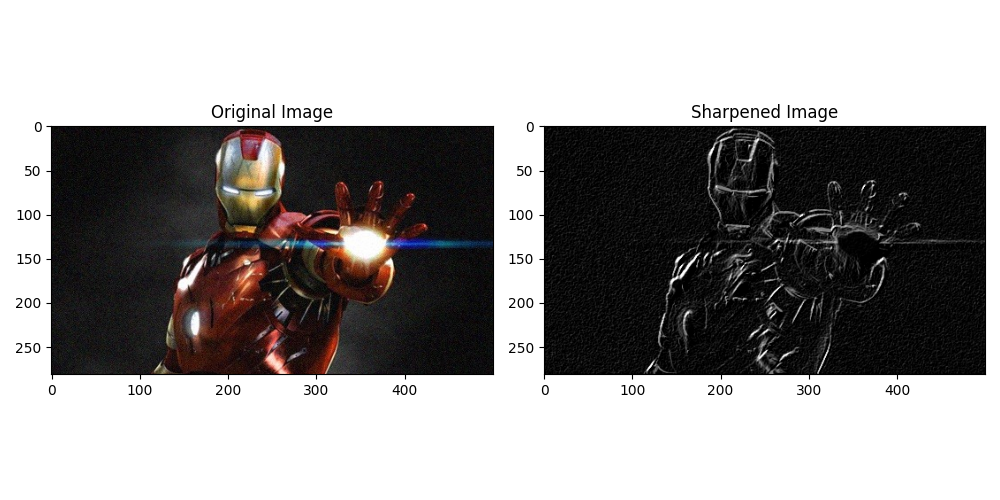
在上述代码中,我使用了自定义的Sobel算子来对图像进行锐化处理。Sobel算子是一种常用的边缘检测算子,它可以通过计算图像中每个像素点的梯度值来检测图像中的边缘。
通过观察锐化后的图像,看到图像的边缘得到了突出,并且图像的细节更加清晰。锐化图像可以用于增强图像的边缘和细节,使图像更加鲜明和有视觉冲击力。
基于TensorFlow卷积神经网络MNIST手写体数字图像分类
使用TensorFlow中的Keras API构建了一个简单的卷积神经网络(CNN)模型。模型包含了一个卷积层、一个池化层、一个Flatten层、一个全连接层和一个输出层。它使用adam优化器和sparse_categorical_crossentropy损失函数进行模型的编译,并使用训练集对模型进行了5个epoch的训练, 最后进行相应测试并输出图像结果。
1 | import tensorflow as tf |
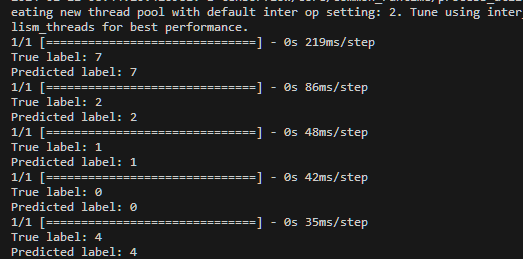
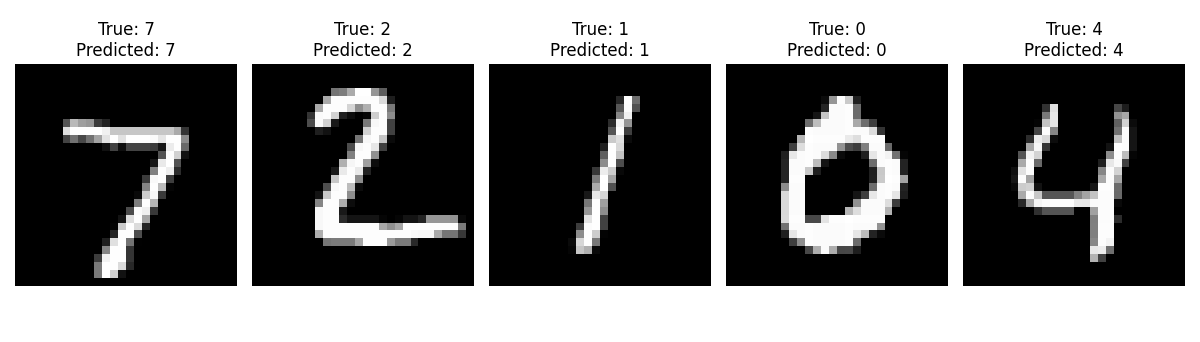
代码使用卷积神经网络模型对手写数字进行分类,并将预测结果可视化显示出来。我们可以看到每个测试图像的真实标签和模型预测的标签, 模型预测结果与真实结果相符合。
深度学习与实践进阶实验
基于无监督自编码器的图像去噪
基于TensorFlow搭建自动编码器对fashion_minist或minist数据集进行图像去噪,展示去噪前后的图像以及损失变化曲线。
首先加载fashion_mnist数据集,并进行了数据预处理,将像素值归一化到0-1之间,并将图像展平为一维向量。
接下来,定义了一个自动编码器模型,其中包含了编码器和解码器部分。编码器部分将输入图像压缩为低维表示,解码器部分将低维表示解码为重构图像。模型使用adam优化器和二进制交叉熵损失函数进行编译。
然后,使用带噪声的训练数据对自动编码器进行训练。训练过程中使用了回调函数来保存最佳模型和提前停止训练。
训练完成后,加载最佳模型并对带噪声的测试数据进行去噪。将去噪前后的图像进行可视化展示。
最后,绘制训练过程中的损失变化曲线。
1 | import numpy as np |
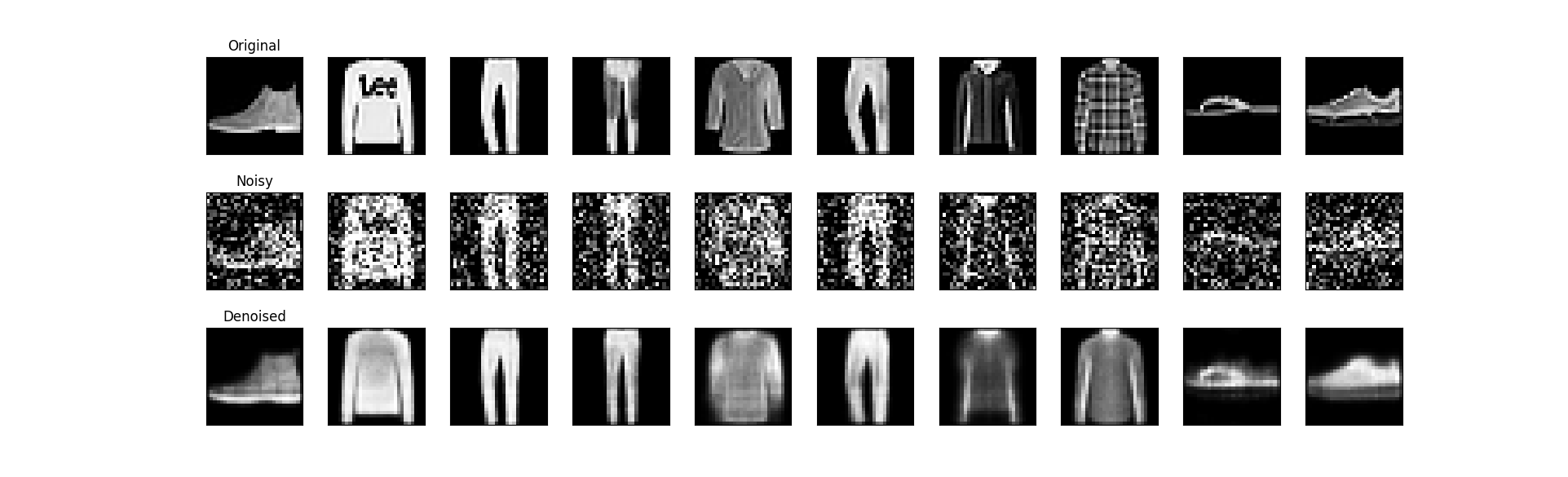
可以观察到自动编码器是如何去除加噪图像中的噪声并恢复原始图像的细节。
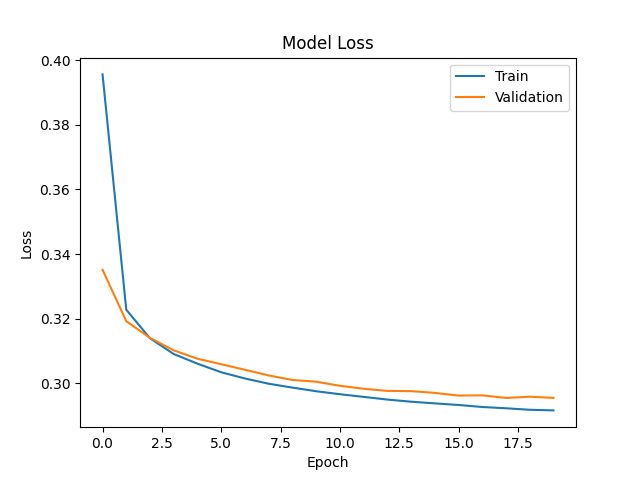
两者之间的差异很小,模型具有良好的泛化能力。训练损失和验证损失都随着训练的进行而下降,模型正在学习并逐渐改善。损失曲线平稳下降,说明模型在学习过程中相对稳定。
基于深度卷积神经网络的迁移学习
- 不使用迁移学习, 直接训练一个新的神经网络, 计算测试集上的准确率
代码使用了一个简单的卷积神经网络模型来进行CIFAR-10的图像分类。首先加载CIFAR-10数据集,然后进行数据预处理,将像素值缩放到0到1之间。接下来构建模型,包括多个卷积层和全连接层。然后编译模型,指定优化器、损失函数和评估指标。最后使用训练集对模型进行训练,并使用测试集评估模型性能。
1 | import tensorflow as tf |

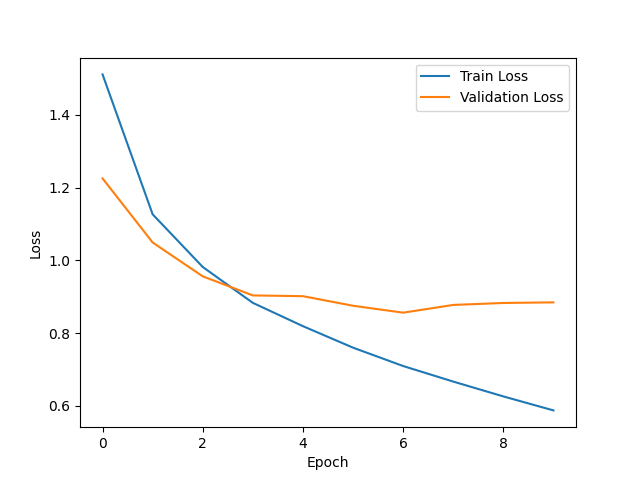
验证损失和训练损失之间的差值逐渐增大时,模型过拟合数据, 在未见过的新数据上的表现较差。能是由于模型的复杂性过高, 训练量过少。
- 使用VGG16模型和相同的数据集、参数进行迁移学习,计算测试集上的准确率
1 | import tensorflow as tf |

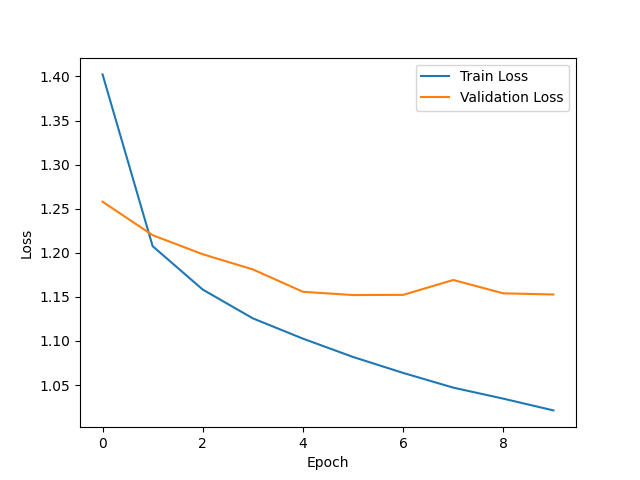
损失曲线有起伏,在训练过程中损失值出现波动,模型在训练过程中难以收敛。对比可以发现,本次实验不使用迁移学习的准确率较高,可能是因为模型的架构或参数选择不合适。
基于深度学习的图像风格迁移
使用基于TensorFlow利用预训练的深度卷积网络(VGG19)完成图像风格迁移。
1 | import tensorflow as tf |
这段代码首先加载并预处理内容图像和风格图像,然后使用预训练的VGG19模型提取这些图像的特征。接着将内容图像作为初始图像,并在每个训练步骤中,根据内容损失和风格损失来更新这个图像。在训练过程中,会保存每个epoch的生成图像和损失值。最后展示内容图像、风格图像,以及训练中不同迭代次数的图像, 并绘制损失曲线。

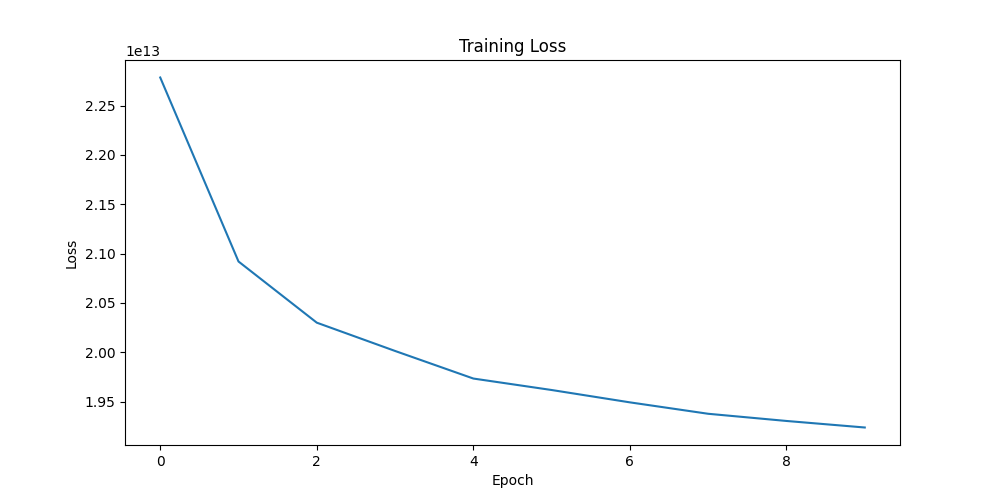
可以看到在steps_per_epoch为500, 共10个epoch的情况下,每次迭代生成的图像会逐渐接近目标风格,并保留内容图像的特征。平均损失曲线逐渐下降并趋于稳定,表示模型正在有效地学习从内容图像到目标风格的转换。
深度学习与实践创新实验
基于TensorFlow搭建卷积神经网络进行花卉图像分类
本次使用的数据集是来自Kaggle的Flowers Recognition数据集,包含了5种不同类型的花朵:雏菊(daisy)、蒲公英(dandelion)、玫瑰(rose)、向日葵(sunflower)和郁金香(tulip)。每种花朵都有多张图片,图片的大小和形状各不相同。
我使用ImageDataGenerator对花朵图片数据集进行预处理和数据增强,创建卷积神经网络模型用于花卉分类任务。模型训练完成后,保存模型并绘制训练和验证的损失和精度曲线。
训练好保存的模型之后会用于应用程序。
1 | import tensorflow as tf |
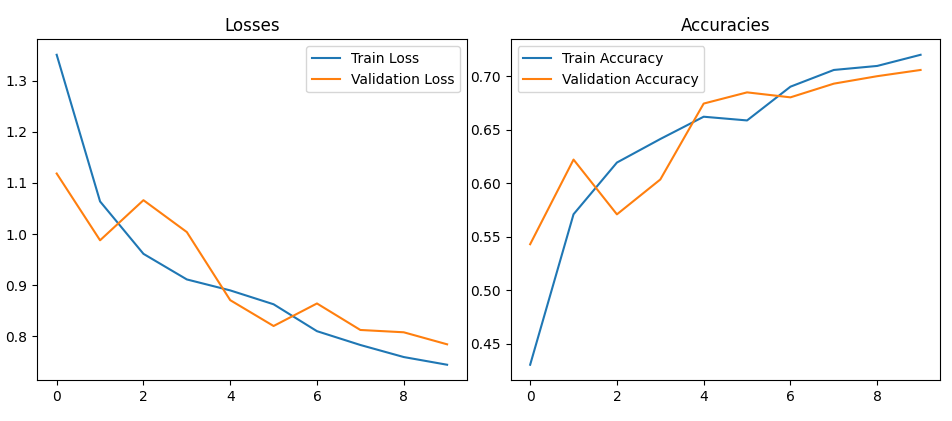
损失曲线在不断下降,准确度不断上升, 模型较稳定可靠。
我写了一个基于PyQt5的桌面应用,使用上文预训练的TensorFlow模型来对用户选择的花朵图片进行分类。在用户界面中,用户可以点击按钮选择图片,然后应用程序会显示选中的图片,并使用模型预测图片中花朵的种类。预测结果会显示在界面上。在后台,应用程序首先加载预训练的模型,然后在用户选择图片后,将图片调整到模型需要的尺寸,然后将图片转换为模型可以处理的数组格式,最后使用模型进行预测。
1 | import sys |
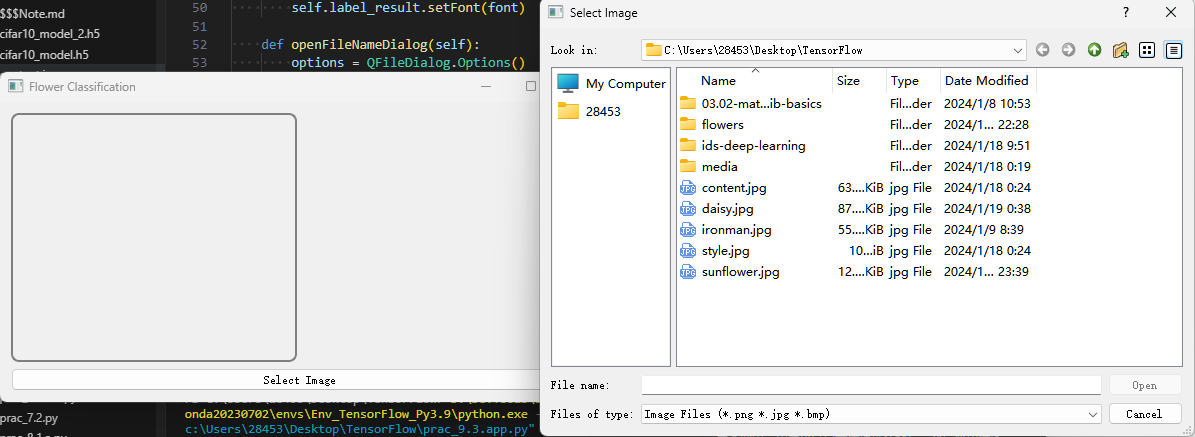
运行代码会打开UI界面, 点击下方Select Image图片选择要预测的图。
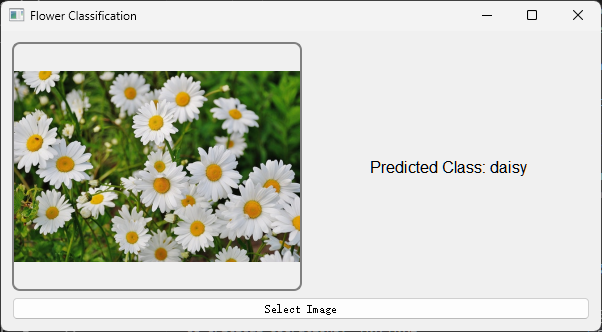
选择图片后会在左侧框内显示, 后台会根据模型进行预测,并返回结果.
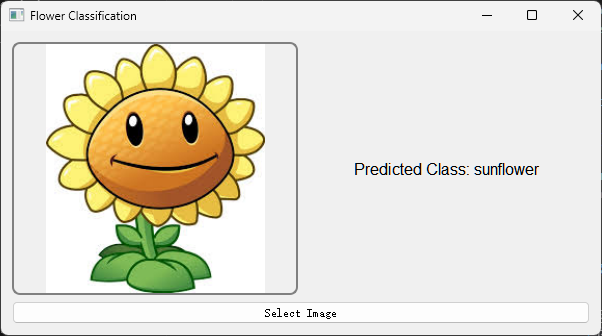
可以看到结果是准确的。
